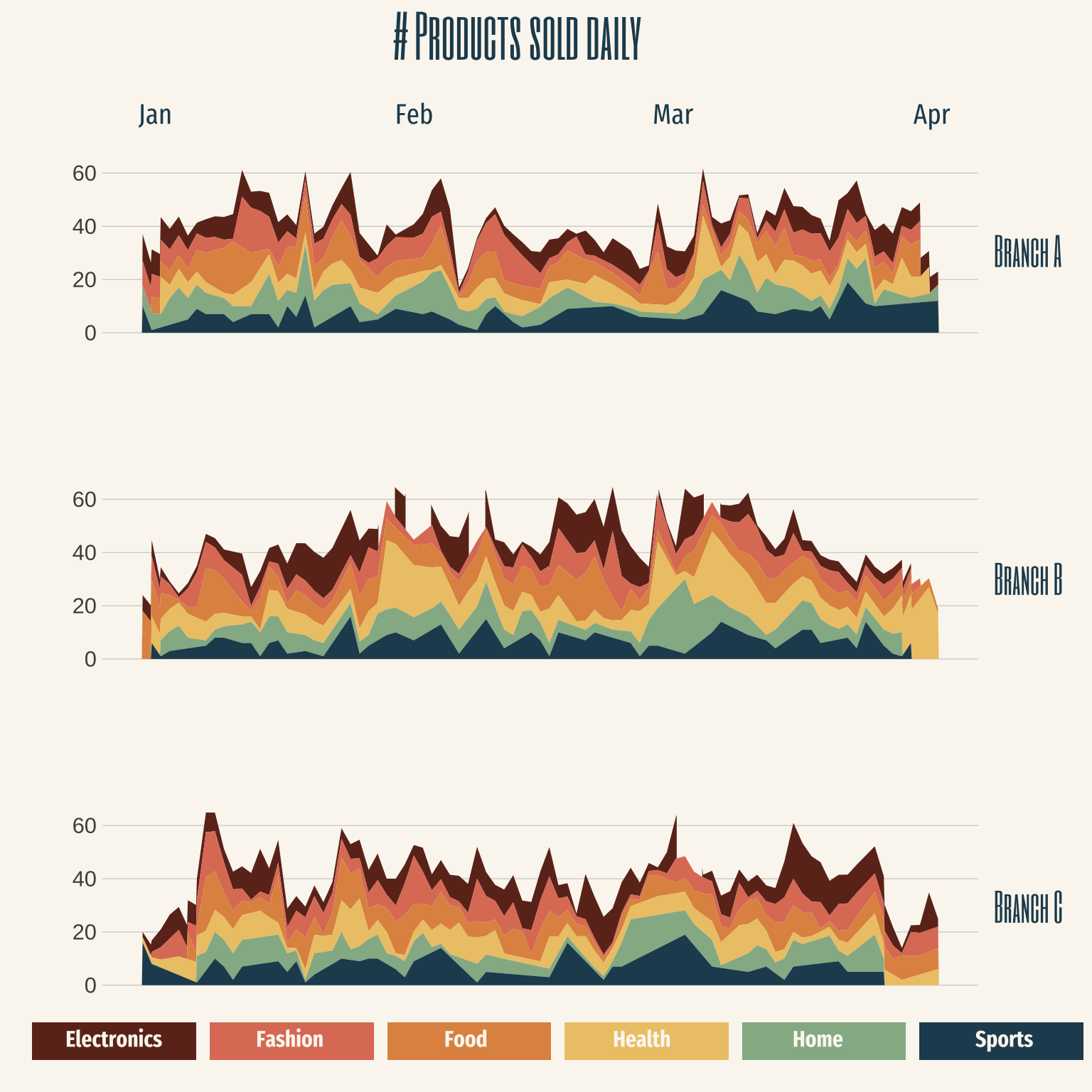
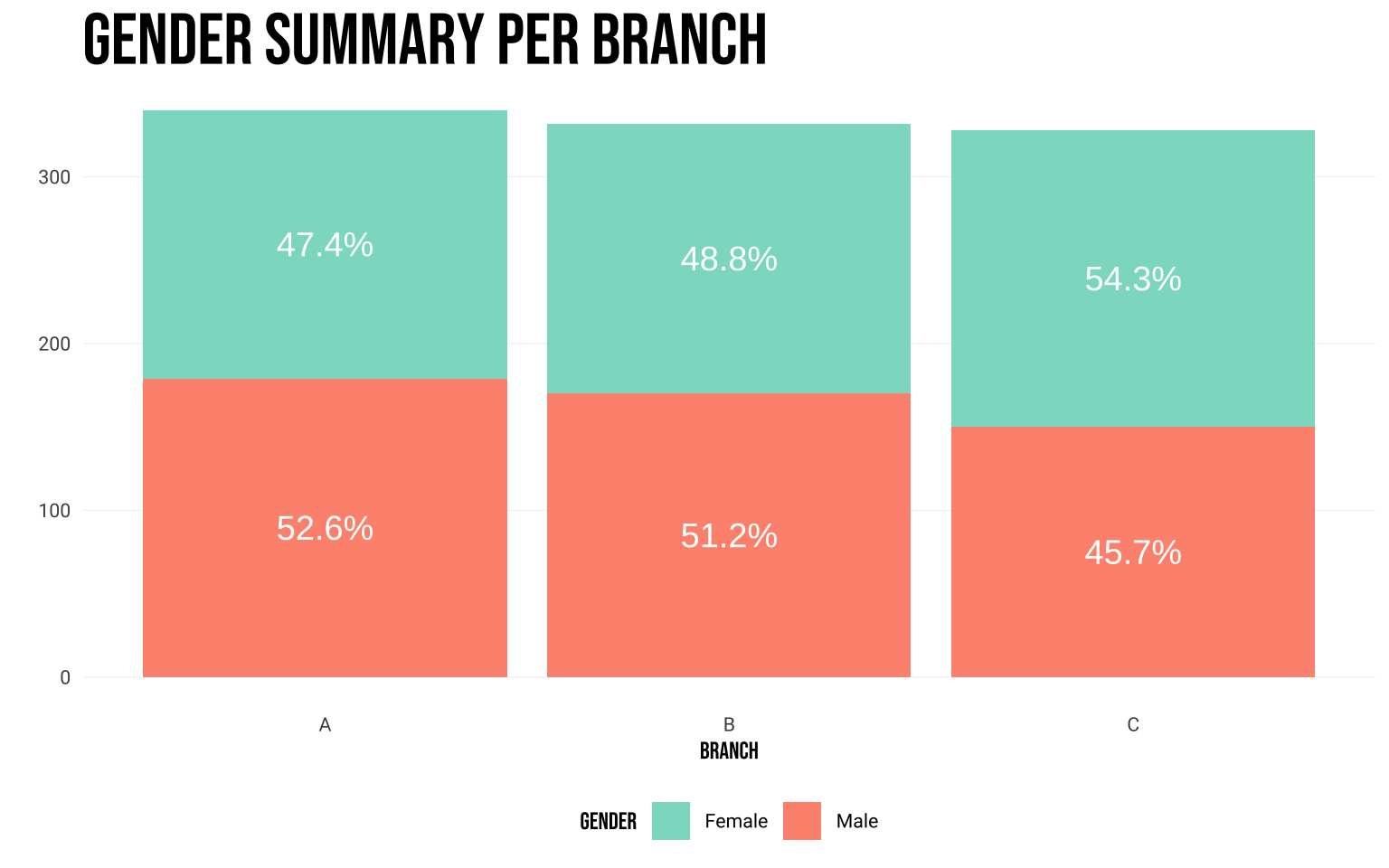
library (ggplot2)library (cowplot)library (dplyr)library (hrbrthemes)source ("helper_functions.R" )# Let's aggregate the data <- dataset |> mutate (formatted_date = lubridate:: mdy (Date)|> group_by (Branch, formatted_date, ` Product line ` ) |> summarise (n_products_sold = sum (Quantity),.groups = "drop" # A function that we can use to plot the sales for the products at any branch <- function (data, branch) {|> filter (Branch == branch) |> ggplot (aes (x = formatted_date, y = n_products_sold, fill = ` Product line ` )) + geom_area () + scale_fill_manual (values= c ("#6d2f20" , "#df7e66" , "#e09351" , "#edc775" , "#94b594" , "#224b5e" )) + theme_ipsum () + theme (legend.position = "none" ,axis.text.x = element_blank (),panel.grid.major.x = element_blank (),panel.grid.minor = element_blank ()+ labs (x = "" , y = "" ) + ylim (0 , 65 )# Lets create the three individual plots <- stream_plot (data_product, "A" ) + theme (legend.position = "none" )<- stream_plot (data_product, "B" )+ theme (legend.position = "none" )<- stream_plot (data_product, "C" ) + theme (legend.position = c (0.52 , - 0.25 ),legend.direction = "horizontal" ,legend.text = element_blank (),legend.title = element_blank (),legend.key.height = unit (0.75 , "cm" ),legend.key.width = unit (3.1 , "cm" )+ guides (fill = guide_legend (nrow = 1 )) # Putting everything together ggdraw (plot_grid (plot_a, plot_b, plot_c, ncol= 1 )) + theme (plot.background = element_rect (fill= "#fbf7f0" , color= "#fbf7f0" ),plot.margin = margin (50 , 30 , 10 )+ draw_text (text = "# Products sold daily" , x= 0.5 , y= 1.06 , fontface= "bold" , size= 30 , family= font1, color= "#224b5e" ) + draw_text (text= "Jan" , x= 0.15 , y= 0.98 , size= 15 , family= font2, color= "#224b5e" ) + draw_text (text= "Feb" , x= 0.4 , y= 0.98 , size= 15 , family= font2, color= "#224b5e" ) + draw_text (text= "Mar" , x= 0.65 , y= 0.98 , size= 15 , family= font2, color= "#224b5e" ) + draw_text (text= "Apr" , x= 0.9 , y= 0.98 , size= 15 , family= font2, color= "#224b5e" ) + draw_text (text= "Electronics" , x= 0.11 , y= 0.035 , size= 12 , family= font2, fontface= "bold" , color= "#fbf7f0" ) + draw_text (text= "Fashion" , x= 0.28 , y= 0.035 , size= 12 , family= font2, fontface= "bold" , color= "#fbf7f0" ) + draw_text (text= "Food" , x= 0.45 , y= 0.035 , size= 12 , family= font2, fontface= "bold" , color= "#fbf7f0" ) + draw_text (text= "Health" , x= 0.62 , y= 0.035 , size= 12 , family= font2, fontface= "bold" , color= "#fbf7f0" ) + draw_text (text= "Home" , x= 0.79 , y= 0.035 , size= 12 , family= font2, fontface= "bold" , color= "#fbf7f0" ) + draw_text (text= "Sports" , x= 0.97 , y= 0.035 , size= 12 , family= font2, fontface= "bold" , color= "#fbf7f0" ) + draw_text (text= "Branch A" , x= 0.96 , y= 0.84 , size= 20 , family= font1, hjust= 0 , color= "#224b5e" ) + draw_text (text= "Branch B" , x= 0.96 , y= 0.505 , size= 20 , family= font1, hjust= 0 , color= "#224b5e" ) + draw_text (text= "Branch C" , x= 0.96 , y= 0.17 , size= 20 , family= font1, hjust= 0 , color= "#224b5e" )